

Multiple GPU Dedicated Server Rental
Accelerate AI training, LLM inference, scientific computing, and 3D rendering with our multi-GPU servers. Exclusive GPU access with optional NVLink ensures maximum multi-GPU efficiency. High AI framework compatibility, 99.9% uptime, and 24/7 expert GPU support.
Rent Remote Multiple Graphics Card Servers
Diverse range of multi GPU dedicated servers delivers unparalleled computing speed and parallel processing capabilities, ideal for applications that demand massive computational power.
Enterprise Multi-GPU Dedicated Server - 3xV100
- GPU Model: 3 x V100
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 1000Mbps Unmetered
- GPU Memory: 16 GB HBM2
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Multi-GPU Dedicated Server - 3xRTX A5000
- GPU Model: 3 x RTX A5000
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 1000Mbps Unmetered
- GPU Memory: 24 GB GDDR6
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Multi-GPU Dedicated Server - 2xRTX 4090
- GPU Model: 2 x RTX 4090
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 1000Mbps Unmetered
- GPU Memory: 24 GB GDDR6X
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Multi-GPU Dedicated Server - 2xRTX 5090
- GPU Model: 2 x RTX 5090
- CPU: 44-core Dual E5-2699v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 1000Mbps Unmetered
- GPU Memory: 32 GB GDDR7
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Multi-GPU Dedicated Server - 3xRTX A6000
- GPU Model: 3 x RTX A6000
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 1000Mbps Unmetered
- GPU Memory: 48 GB GDDR6
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Multi-GPU Dedicated Server - 4xRTX A6000
- GPU Model: 4 x RTX A6000
- CPU: 44-core Dual E5-2699v4
- Memory: 512GB RAM
- Disk: 240GB SSD+4TB NVMe+16TB SATA
- Bandwidth: 1000Mbps Unmetered
- NVLink: 2xNVLink
- GPU Memory: 48 GB GDDR6
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Multi-GPU Dedicated Server - 4xA100
- GPU Model: 4 x A100
- CPU: 44-core Dual E5-2699v4
- Memory: 512GB RAM
- Disk: 240GB SSD+4TB NVMe+16TB SATA
- Bandwidth: 1000Mbps Unmetered
- NVLink: 6xNVLink
- GPU Memory: 40 GB HBM2
- IP: 1 Dedicated IPv4
- Location: USA
Reasons to Choose our Multiple GPU Servers
Our state-of-the-art Multi-GPU Servers are designed to meet the most demanding computational needs of modern businesses and research institutions.
Parallel Computing with Multi-GPU Interconnect
High-speed GPU interconnect enables efficient data and model parallelism across multiple GPUs, significantly improving compute utilization and scaling efficiency for AI training, inference, and HPC workloads.
Distributed Training with NVLink
Optional NVLink support delivers high-bandwidth, low-latency GPU-to-GPU communication, reducing synchronization overhead and accelerating distributed training for large-scale AI models and multi-GPU workloads.
Best Cost-Performance
Achieve the lowest cost per GPU and per GB of memory/disk with fully dedicated hardware. No virtualization overhead and no hidden fees, maximizing value for every dollar spent on gpu rental.
High-Speed Storage & RAM
Large RAM and high-capacity NVMe SSDs are included by default, ensuring fast data throughput and stable performance for LLM inference, AI training, and data-intensive workloads.
Reliable and Secure
Backed by 7 years of GPU server operation experience and premium components. Enjoy 99.9% uptime, data integrity, and optional firewall protection.
Expert Support and Maintenance
Our GPU specialists provide 24/7 support from deployment to ongoing maintenance. Professional assistance is always included at no extra cost.
Unlock the Potential of Multi-GPU Servers
Multi GPU servers are designed for workloads that demand scale, parallelism, and sustained performance — from LLM training and inference to enterprise-grade AI and HPC applications.
AI Model Training & Inference
Large language models (7B–70B) and multi-task deep learning workloads require massive GPU compute and VRAM. Multi-GPU dedicated servers enable data and model parallelism, faster parameter synchronization, and stable long-running training without resource contention. Compatible with TensorFlow, PyTorch, and Hugging Face.
Explore Stable Diffusion Multiple GPU, Ollama Multiple GPU, and AI Image Generator Multiple GPU.
3D Rendering & Visual Effects
Professional 3D rendering and visual effects pipelines rely on large VRAM capacity and parallel GPU processing. Multi-GPU dedicated servers accelerate frame rendering, scene compilation, and high-resolution output — significantly reducing render times and improving workflow efficiency for studios and creative teams.
Explore Rendering GPU Hosting.
Scientific Computing & HPC
Scientific simulations, matrix operations, and numerical modeling demand parallel compute performance and low-latency inter-GPU communication. Multi-GPU physical servers provide predictable scaling, high compute density, and stable throughput — ideal for HPC workloads that cannot tolerate virtualization overhead or shared resources.
Multi-Tenant & Virtualization
Multi-GPU physical servers support GPU partitioning and virtualization for isolated workloads while maintaining consistent performance. Dedicated hardware ensures predictable resource allocation across tenants — suitable for internal platforms, managed services, and environments requiring strict performance isolation.
Multi-GPU Server AI Model Selection
Our multi-GPU servers are tailored to different model sizes and workloads. Refer to the tables below to find the recommended GPU setup based on your model requirements. Sample test data for some of our configurations are shown in the figure.
Medium-Sized Models (7B–16B)
This 2×RTX 4090 dual gpu setup is ideal for medium-sized models (7B–16B), model fine-tuning, and high-concurrency inference. It delivers excellent performance while maintaining cost efficiency.
Large Models (14B–32B)
The 2×A100 multi-GPU configuration is perfect for large models (14B–32B) requiring multi-task concurrent inference or model training. It ensures stable performance and high throughput.
Extra-Large Models (32B–72B)
The 4×A6000 multi-GPU server is best for extra-large models (32B–72B), enterprise-scale training, and high-load inference. It maximizes performance for demanding workloads.
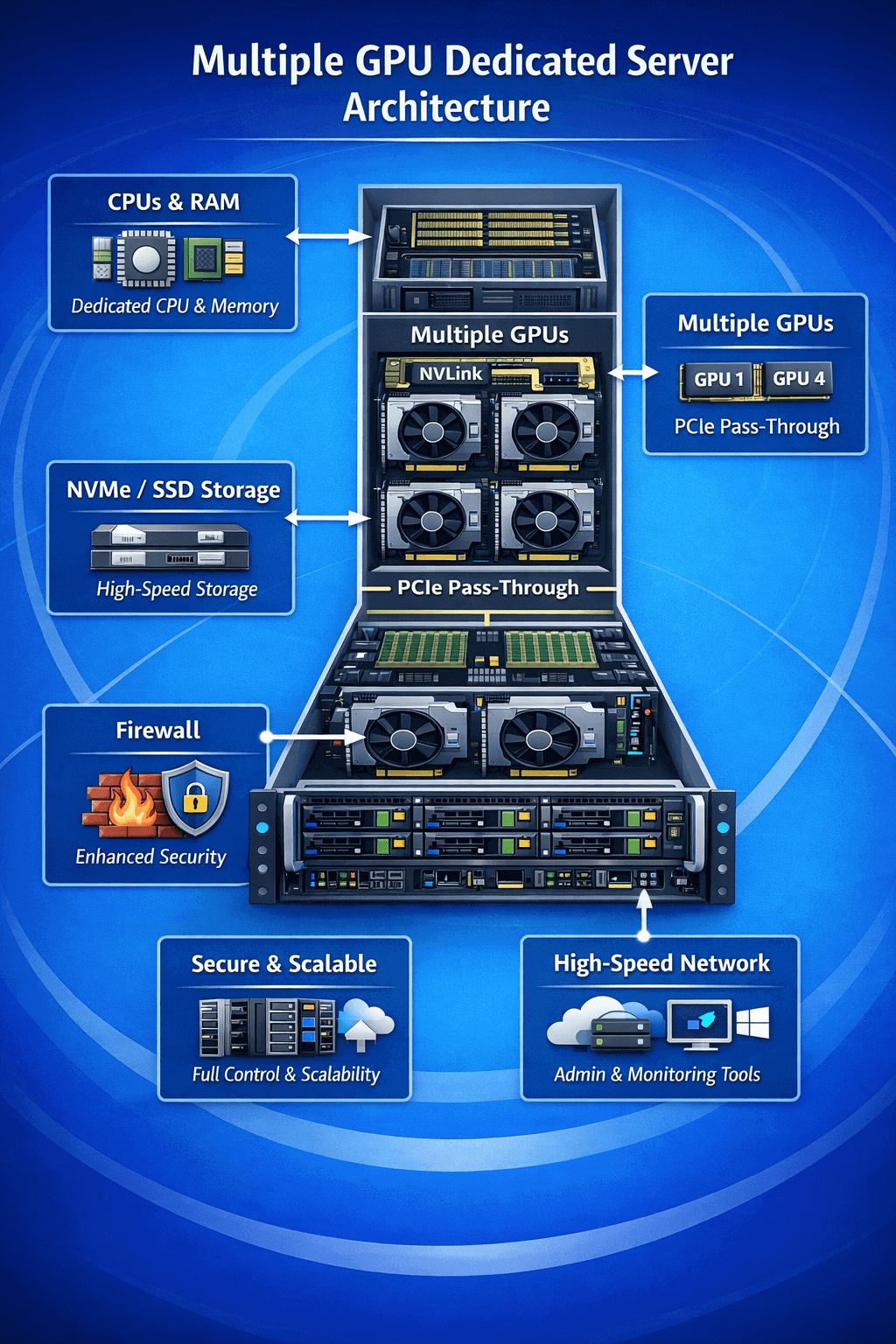
Multi GPU Server Architecture & Key Features
Predictable Performance
Stable throughput under sustained high-load workloads. PCIe passthrough ensures direct GPU access, with optional NVLink for higher inter-GPU bandwidth.
Production-Ready Environment
Pre-optimized GPU drivers and CUDA stack enable faster deployment from testing to production.
Simplified Multi-GPU Management
Unified architecture makes multi-GPU workloads easier to monitor, and manage.
Secure Network
Optional firewall and network isolation protect GPU workloads from unauthorized access. Custom rules allow clients to manage network access and secure their data.
FAQs of Multiple GPU Servers
What is multiple GPU server?
What are the rentable operating systems GPU servers?
Is your GPU card shared or dedicated?
Do you support hourly billing for multiple GPU dedicated server?
If you need GPU services with hourly billing for flexible, short-term usage, please contact our sales team to check available plans.
Can I add or replace GPUs on my multi-GPU dedicated server?
What's the difference between Nvidia Ampere, Volta, and Ada Lovelace?
1. Nvidia Ampere: GPU architecture published in 2020, focused on gaming and AI, with advanced ray tracing and AI capabilities.
2. Nvidia Volta: Previous GPU architecture (2017), optimized for high-performance computing (HPC) and AI, featuring Tensor Core technology for deep learning tasks.
3. Ampere succeedes both the Volta and Turing architectures. It is designed to address the most critical scientific, industrial, and business challenges by accelerating AI and high-performance computing (HPC) tasks. It excels at visualizing complex content for creating innovative products, immersive narratives, and futuristic cityscapes. With a focus on elastic computing, Ampere delivers unmatched acceleration for extracting insights from massive datasets across all scales.
What data centers can I choose for multi-GPU servers?
What common applications can I run on multi-GPU servers?
Contact Us for Custom GPU Solutions
Still can't find the dedicated server with GPU rental that fits your needs? Contact us for personalized recommendations and alternative solutions.